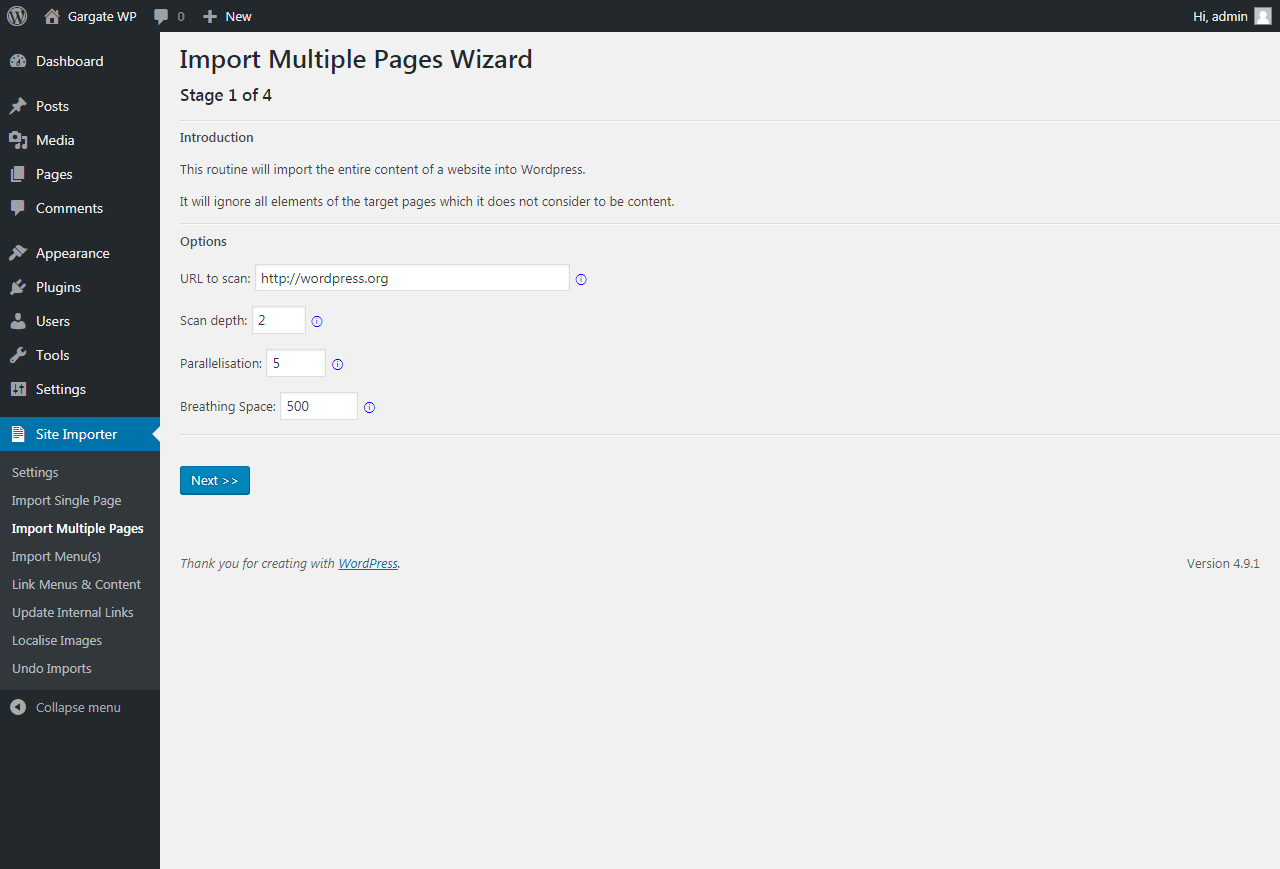
Importing Multiple Pages
Step 1 of 4
The ability to import multiple pages from any website, directly into WordPress, just by entering a URL, is one of the plugin’s most useful features as it will save you so much time.
There are a few initial configuration options you may need to be aware of:
- URL to scan
- Scan depth
- Parallelisation
- Breathing Space
URL to Scan
Enter a webiste address, including the leading https:// or https:// The tool will retrieve the web page found at this URL It will then automatically follow all internal links within it.
Scan depth
Controls the depth to which the scan will run. A setting of 1 will only detect the entered url and all pages linked from that URL. A setting of 2, will then also detect all pages linked from all of the above pages. A setting of 3, will then also detect all pages linked from all of the above pages. Note that the higher the setting, the more work the system needs to do and the longer it will take.
Parallelisation
Controls how many pages are checked at once. Increase this setting to process more pages at the same time. You can dramatically reduce the time it takes to import an entire website into WordPress by using this setting.
Breathing Space
Controls how long (in milliseconds) to pause between each parallel batch of requests. This helps to avoid swamping the web server you are checking.
Once you’re happy with the settings to be applied, click Next to continue.
Import Multiple Pages – Step 1
(click image to zoom)
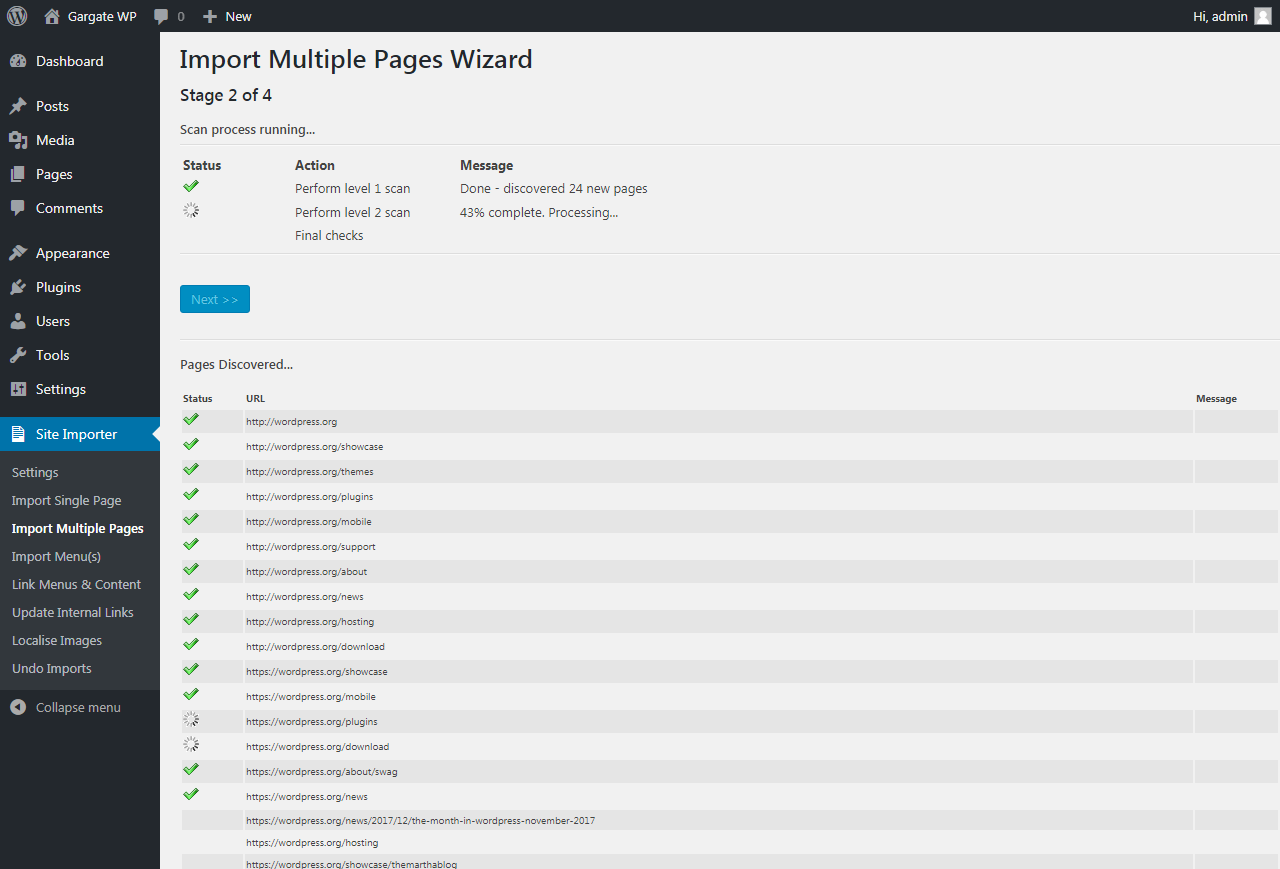
Step 2 of 4
The system will begin to scan the website entered and automatically identify all of the pages on it.
It will provide a progress update as it runs.
Once complete, click Next to continue.
Import Multiple Pages – Step 2
(click image to zoom)
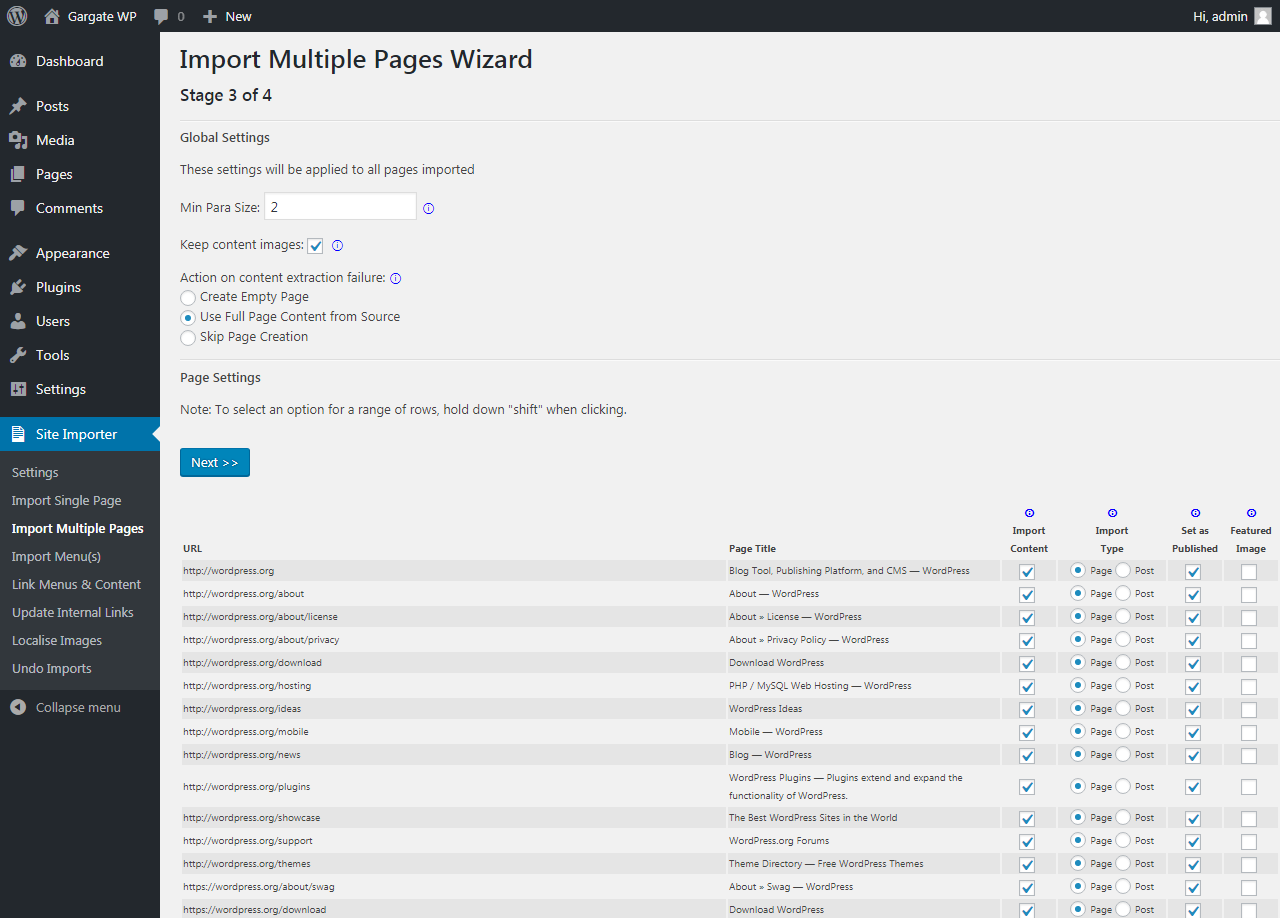
Step 3 of 4
Having automatically identified all of the content available to import into WordPress, you now have options to control how it is migrated.
The settings at the top of the page cover all imports. These options are:
- Min Para Size
- Keep Content Images
- Action on content extraction failure: (Create Empty Page|Use Full Page Content from Source|Skip Page Creation)
Additionally, you can apply certain settings to a range of pages (hold down shift when clicking to select/unselect an entire range):
- Import Content
- Import Type (Page|Post)
- Set as Published
- Featured Image
Min Para Size
Some websites output small placeholder elements which are later replaced dynamically with special components. These placeholders can get picked up by the extraction routine. This setting controls the minimum size (in characters) that a paragraph must reach to be imported. Consider lowering this value if small paragraphs are being ignored. Consider raising this value if odd text is appearing in the results.
Keep Content Images
If ticked, all image tags in the content will be retained and can be localised (i.e. added to the Media Library) by the Localise Images feature. If not ticked, all images will be stripped from the content as it is imported.
Action on content extraction failure
Occasionally, Site Importer may not be able to determine the actual content on a web page. This usually happens where the proportion of actual content on the page is very small. You can choose to either create an empty ‘place holder’ page/post for such failures, take the full page content from the source or to skip the page creation entirely.
Import Content
If ticked, this content will be imported automatically into WordPress from the source page. Otherwise it will be skipped.
Import Type
Determines whether to import content as a WordPress page or post.
Set as Published
Determines whether to set the newly imported page to a status of published rather than draft.
Featured Image
If a dominant image (normally the first) can be identified on the webpage, this may be set as the page or post’s featured image. This is useful for blog posts where you desire an image to appear in the blog article listings (or RSS feeds).
Once you are happy with your selections, click Next to continue.
Import Multiple Pages – Step 3
(click image to zoom)
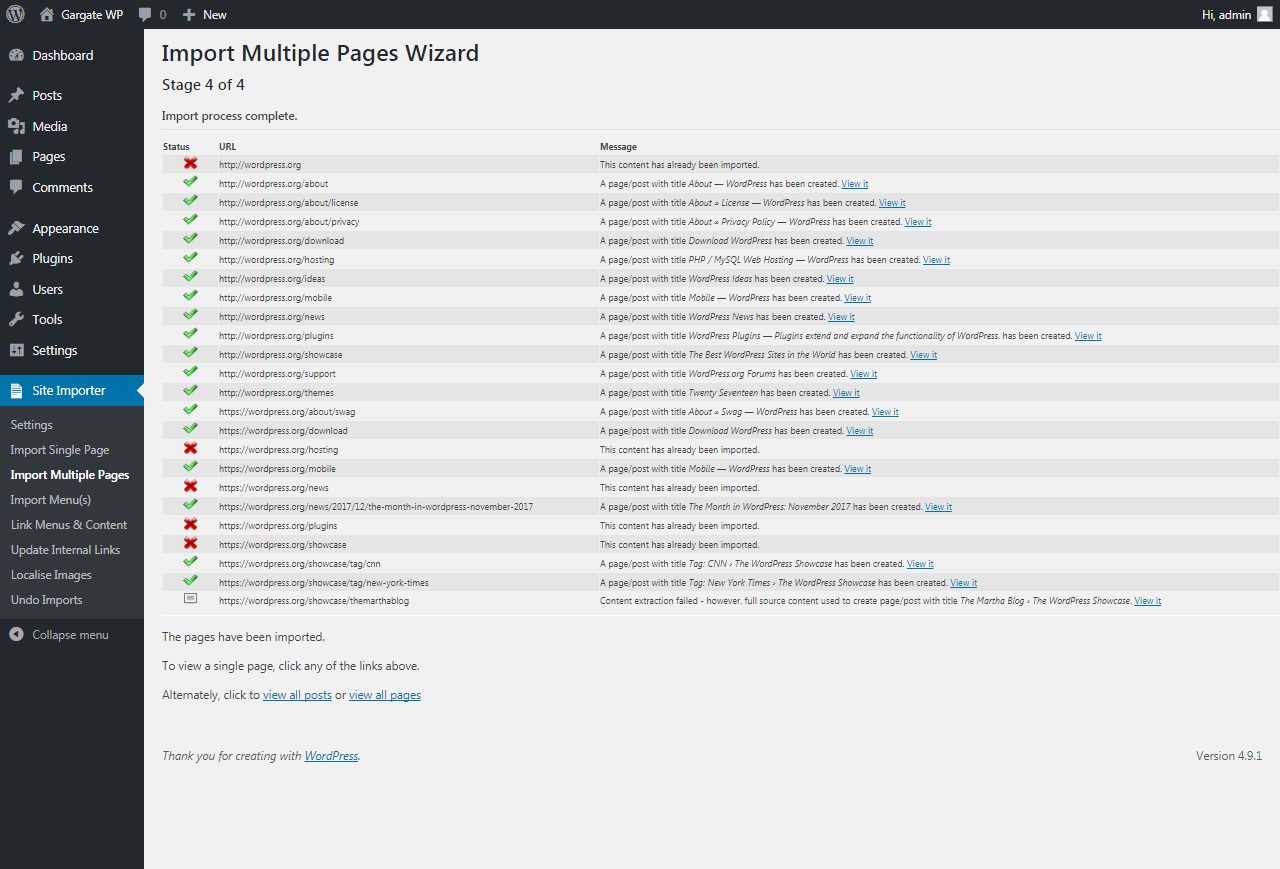
Step 4 of 4
The system will now import the content from all of the selected pages directly into WordPress, creating new pages/posts for each item.
Any issues will be highlighted in the message column.
Once import is complete, a link is displayed, allowing each individual page/post to be viewed. These can also be viewed in the normal way through WordPress’ Pages and/or Posts menu options.
Limitations on Content Import
Canonicalization
Occasionally links may point to locations that end up routing to the same content. For example, it is very common for domain.com, www.domain.com and www.domain.com/index.html to all point to the same page. The WP Site Importer plugin cannot be sure the content is identical until it has followed the link and extracted the content and compared it with content it has already imported. If duplicate content is identified (pages with the same title, same content and similar URLs), it will not be imported.
Mime Types
Some links will point to locations which are just not suitable for import as pages or posts. For example, they may point to PDFs, videos, images and other items that would more properly belong in the Media Library. One cannot rely solely on the file extension to identify the type of file and, indeed, it would be insecure to do so. The only way the WP Site Importer plugin can be sure a file contains valid HTML is to request the file, check it’s mime type and attempt to process the contents. So, occasionally, content may get skipped with an error message explaining that the “mime type” is not suitable.
Content Identification Issues
The WP Site Importer plugin uses a form of artificial intelligence to identify the actual content on a page – distinguishing it from other elements such as menus, banners, footer links, embedded script code and so on. As all websites and perhaps different sections within a single website are different, this is quite complex task.
In order to “zone in” on the actual content, a reasonable amount of real, well written, formatted content is necessary. If this cannot be found, or other elements trigger a false positive, then the plugin may fail to extract the content. On such rare occasions, the configuration options will control what happens. Either the page creation will be skipped, or a blank page created as a placeholder, or the plugin will fallback to importing the full content of the body tag of the source.
Non HTML based websites
Although the vast majority of websites physically have the content embedded within the pages served to the visitor’s browser, not all websites work this way. Some sites, such as those written in Angular or React use JavaScript to retrieve the page content and then directly manipulate the browser’s DOM model to render the content. The WP Site Importer plugin cannot currently extract such content.
Import Multiple Pages – Step 4
(click image to zoom)